1.はじめに
統計学やデータサイエンスが持て囃されるようになって久しい。
しかし、社会問題に関する議論で統計やデータを重視する立場の人々の間では、データや統計に対するある誤解が流布しているように思う。
その誤解とは主に以下のようなものだ。
・統計やデータは客観的な事実であり、個人の主観的な意見よりも信頼できる。
・統計やデータを根拠にした主張は、そうでない主張より正しい(確率が高い)。
・統計やデータを使えば、個人的な体験を根拠にした感情論や主観的な感想を述べるだけの議論を避けることができ、有意義な議論をすることができる。
おそらく、多少なりともデータリテラシーがある人であれば上に挙げた三つの思い込みは間違いだというのが分かるだろう。もしくは、条件付きであれば正しいが現実で条件を満たすことは難しいと言うかもしれない。
しかし、これらが正しいと思っている人はけして少なくない。
特に、統計やデータを使って個人的体験を根拠にして、主観的な感想や感情を意見として述べる人を批判する人はかなりこの傾向が強い。
統計やデータに対して人々がどのような勘違いをしているか、カール・T・バーグストロームは適切に述べている。
言葉は頭の中で組み立てられたもの。数字はどうだろう。自然界からそのまま取り出したような印象だ。言葉は主観的で、いくらでも真実をねじ曲げたりぼやかしたりできる。直感と感情が盛り込まれ、表現力が駆使される。数字は違う。精度が高く、科学的アプローチに結びついているはずだ。誰が報告しても変わりないはず、だから信用できそうだ。
数字のほうが信頼できるという理由で、疑り深い人々は「とにかくデータだけを見たい」、「生データを見せろ」「測定値がすべてをあらわしている」と口にする。「データは嘘をつかない」という言い回しもよく聞く。ただ、ここにも落とし穴がある。(『デタラメ~データ社会の嘘を見抜く~』p114)
")
今回の記事では、まず統計やデータは優れて客観的な事実であるというのは思い込みに過ぎないことを説明示していきたい。
結論から先に述べよう。
統計やデータは事実そのものではない。
統計やデータは人間によって作られるものだ。人間が解釈した現実を数字によって表現したものが統計やデータなのだ。
これは統計学やデータサイエンスの入門書ではあまり触れられていないことだ。統計やデータとはそもそも何であるかについて、統計教育で軽視される傾向にあることはジョエル・ベストも次のように認めている。
統計はすべての社会行為の産物、社会学者が社会的構成と呼ぶ作用の産物だ。この点はあまりにも明白なように思えるかもしれないが、統計について考えるとき――とくに教えるとき――に忘れたり無視したりしがちだ。(中略)その結果、統計教育は、現実の統計がどのように生まれるかについての考察を軽く扱いがちだ。だが、統計はすべての人々の選択と妥協の産物であり、そうしたことによって形作られ、制約され、ゆがめられるのだ。(『統計という名のウソ』P14)

さて、統計やデータは人間によって作られるものであると説明するために、まず統計がどのように作られるのかについて触れていこう。
2.統計は仮説から生まれる
統計を取る際は仮説を立てて因果モデルを形成する。
仮説を立ててそれを証明する目的で情報収集を行うのだ。仮説や目的なく、いきなりアンケートや調査をするわけではない。
「アンケート調査でもやって実態を調べてみてから議論しよう」といった程度で集められたデータでは結局何が言いたいのか分からないものになる。
何の仮説を立てないでいきなり情報収集をすればどうなるかについては、良い例がある。
以下は、Vigen, T. のウェブサイト(http://tylervigen.com/spurious-correlations)で載せている有名な無意味な統計を中室牧子氏が和訳したものだ。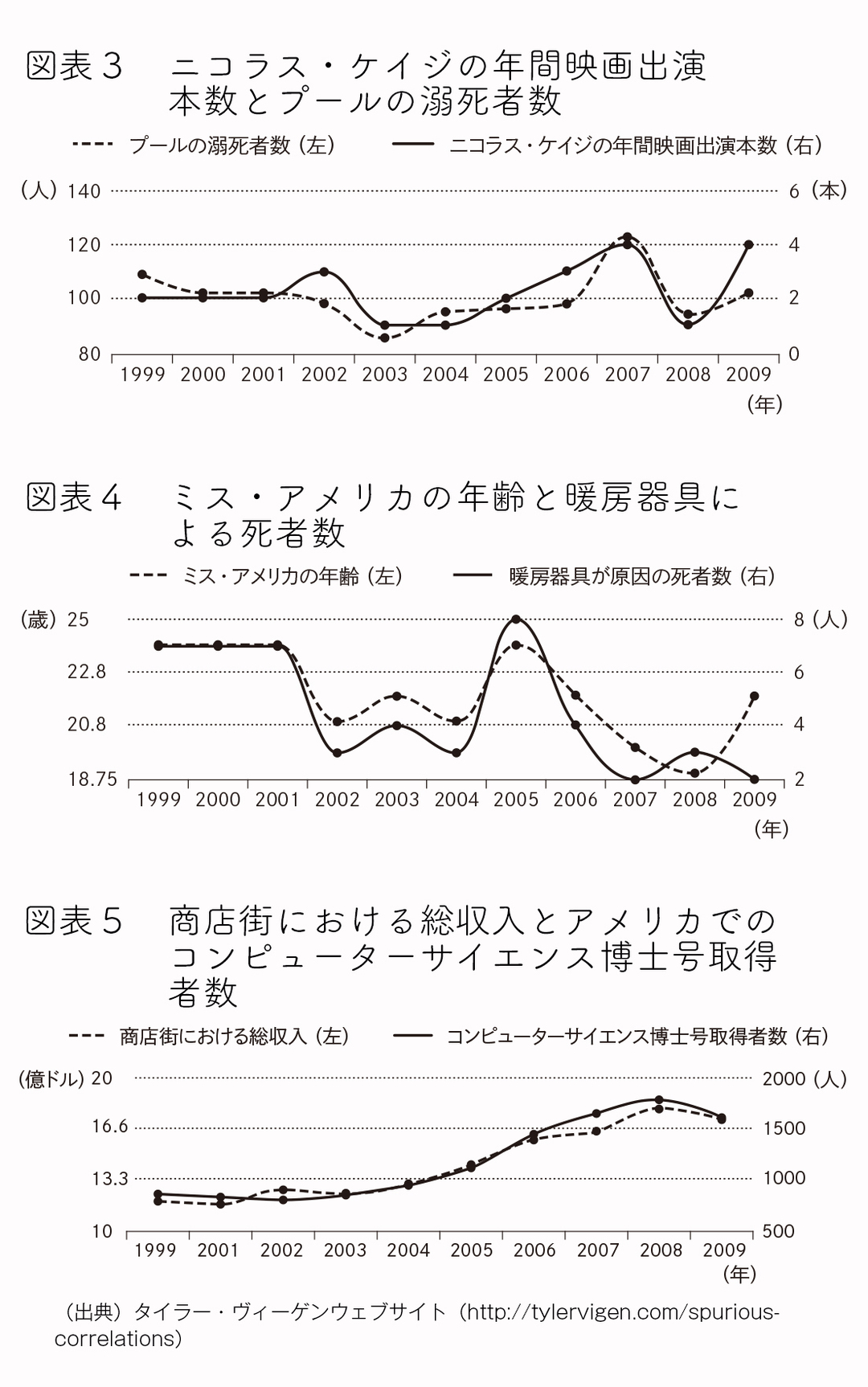
(上の図は「原因と結果」の経済学―データから真実を見抜く思考法にも載っている)
図にある統計のどれもが馬鹿らしいものであることは一目瞭然だ。
まず、ニコラス・ケイジの年間映画出演がプールでの溺死に影響を及ぼすはずがない(逆もありえない)。
商店街における総収入がアメリカでのコンピューターサイエンス博士号取得に何か影響を及ぼすだろうか? ミス・アメリカの年齢が下がると暖房器具による死者も減るのだろうか? どちらもありそうもない。
多くの人が察しているようにこれはただの偶然だ。
このように、統計上は有意なデータを示していてもただの偶然の一致だということがある。
しっかりと仮説を立てそれを検証するという意図がなければ、上の図のように何の訳にも立たない無意味な相関関係ばかりが発見されることとなるだろう。
だから、社会科学の分野では因果関係を推測して仮説を組み立て仮説からの演繹という形で統計が集められる。
つまり統計を取る人間は、仮説の段階で収集すべき情報を選別する必要があるということだ。
言い換えれば、統計を取る人間は自分の仮説に基づいて現実を切り取っているということだ。
仮説の段階で、切り取られる現実の画角が決まる。
統計を取る人間は、仮説を立てた段階で仮説にとって無意味だと思える情報を排除する。つまり、統計の情報は、それを作った人間によってフィルタリングされた情報だ。
しかし、そうしたフィルタリングが常に正しいとは言い切れない。統計を立てた人間が勝手に意味があると思った情報であって、客観的には意味がない情報の可能性は捨てきれない。
仮説では因果関係として想定していたものが実際はただの相関関係だったという場合は少なくない。その場合、統計は嘘の事実を示すことになる。
例えば、昔はコーヒーが心筋梗塞を引き起こすと考えられていたことについて考えてみよう。
コーヒーに含まれるカフェインによる興奮作用や睡眠への影響が心臓に悪影響を与えるのではという仮説の基データが収集され、結果としてコーヒーをよく飲んでいた集団が、あまり飲まない集団よりも心筋梗塞の発生が多くみられたデータが出たのだ。
そのデータだけ見れば、コーヒーが心筋梗塞を引き起こすという仮説を支持しているように思える。
だが、その後の研究でコーヒーをよく飲む人には喫煙している人が多くいたことが分かり、喫煙が心筋梗塞の真の原因であることが分かった。それどころか、喫煙の影響を除外した研究ではコーヒーを飲んでいる人のほうが心筋梗塞になりにくいという結果が得られた。
つまり、コーヒーの飲用と心筋梗塞には正の相関関係があったが、それは因果関係ではなく疑似相関(見かけの相関)で、事実は全くの逆だったのだ。
しかし、当初はコーヒーをよく飲むことが喫煙をすることと関係があるとは推測されていなかった。そのため、喫煙が交絡因子(コーヒーの飲用と心筋梗塞の両方に関係している因子)となっているという考えに至らなかった。
喫煙が真の原因であるという可能性は、仮説の段階で排除されてしまっていたのだ。
私たちは人間であり神様ではない。
すべての交絡因子を考えついて、その影響をすべて除外して統計を取るなんてことは実質不可能だ。もしかしたら、まだ誰も発見していない交絡因子が存在する可能性は常に残る。
また、未測定の交絡因子が複数あり、それらが複雑に絡み合いながら影響を及ぼし合っている可能性だってありえる。世の中には一つの要素が原因となって一方的に影響を与えような関係だけではなく、要素同士が互いに影響を与えて悪循環を起こしたり好循環を起こしたりすることもあるからだ。
だから人間の考える因果モデルは、複雑な現実社会を人間の想像の範囲内に収まる形で簡略化したものにならざるを得ない。
統計の仮説はその簡略化された図式の中で立てられているのだ。
統計は、それを取る者の主観的な現実理解から作られた仮説を基に情報を収集したものだ。
言い換えれば、統計はそれを作った人間の主観を少なからず反映してしまう。
統計から人間の主観的な判断を取り除いて、完全に客観的な事実にすることは不可能だ。
3.統計は表現物である
言葉を使った社会論評は言葉巧みにレトリックを駆使して印象を操作し、それを読む人間を騙しているが、データや統計は数字なのでそのような印象操作が行われることはないと主張する人はいるかもしれない。
しかしそれは間違いだ。
統計やデータも人間によって表現されているものだということを多くの人が忘れている。
表現というものは、言葉によって明言された内容のことだと多くの人が考えているが、そうではない。
日常のコミュニケーションにおいて、ボディランゲージや視線、場合によっては沈黙などが意志の表現になるように、形式上は言葉にしていなくても人は何かを伝えることがある。
例えば、ある人物について次のように説明する人がいたとしよう。
「少なくとも彼は仕事をしている時はいい人だよ。まぁでも、私の知り合い中で一番性格がいい人とは言い難いし、私は個人的には深く付き合いたいと思わないな」
あなたはここからどんな人物像を想像するだろうか?
形式上の内容だけを考えれば、この人物が仕事以外でどんな人なのかは直接明示されていない。この人物の性格は悪いとは言っていない。ただ、1番ではないと言っているだけだ。また、深く付き合いたいと思わない理由も述べていないので、深く付き合いたくない原因が彼にあるとも言っていない。形式上は。
しかし表現には常に言外の意味が付きまとう。
多くの人は、明示されていない部分についてもある程度推察して、それを受け取ってしまうだろう。
「仕事をしている時は良い人」ということは、仕事をしている時以外は良い人じゃないのか? とか、「一番性格がいい人とは言い難い」とわざわざ言っているということはどちらかと言えば性格が悪いということを婉曲に表現しているからか? とか、個人的に深く付きたくないくらい性格が悪いのだろうか? とか疑ってしまうはずだ。
表現は置かれた状況や文脈によって解釈されるからだ。
私たちは、ストレートな表現を使わず、仄めかしたり匂わせたりする表現を知っている。私たちは表現の仕方を変えることで、内容では直接嘘をつかずとも、受け手を誤解させたり騙すことは可能だ。
データが間違っていないならデータは嘘をつかない、というのはデータも表現されるものであるということを完全に無視している。
直接の嘘をつかなくても、受け手側を誤解させ騙すという意味での実質的な嘘なら統計やデータでも可能である。
そうでなければ「誤解を与える統計グラフ」「詐欺グラフ」(Misleading graph)なんて概念は存在しない。印象操作と呼ばれるようなデータの見せ方は存在するのだ。
一つ『あなたの知らない「詐欺グラフ」の世界(随時更新中)|けんけん|note』から例を紹介しよう。
よく分かっていない人も多いですが、棒グラフはその面積で強い印象を与えるため、縦軸の一番下はゼロ。絶対にゼロ起点にしないといけません。(中略)
ゼロ起点のグラフでないとまさに上記のような表現もアリになってしまうわけです。「MRJスゲエ!! 燃費が数分の一!」って、あれ…?
これ、別に嘘じゃないからいいんじゃないの?と思われる人も多いかもしれませんが、では逆にこのグラフで何を言いたいというのでしょうか。20%の減少を、見た目に「20%感」が全くない(むしろ誤解させる)表現にする意味はどこにもありません。
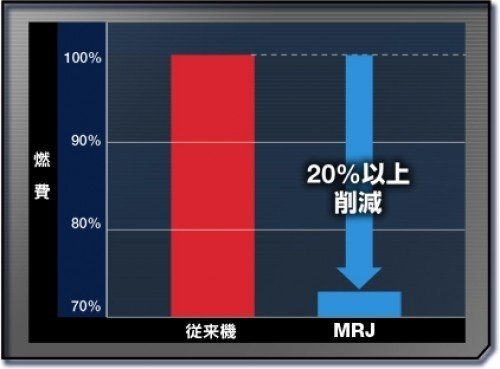
このように全く同じデータでも見せ方は選ぶことが出来る。
統計やデータはその表現の形態によって全く異なる印象を人に与えてしまう。
統計グラフにはデザインがあり、表現としての性質を持っている。だから、統計の数字の配置やグラフのデザインも、人間が適切なものを選ぶ必要がある。
しかし、統計のデザインには決まったルールがあり、言葉の表現と違って正しい表現方法が決まっていると主張する人はいるかもしれない。例えばライファクター(lie factor=嘘の要素)のような指標で正しさは数値化されていて、ライファクターが1に近い(=嘘の要素が少ない)ものを作るのが正しいので、人間がデザインを決めるということが間違いだと言う人はいるかもしれない。
では、ここでライファクターが1(=正常)となるような、それでいて間違った印象を与えてしまうグラフを例に挙げよう。
それは地球温暖化に関するグラフだ。
地球温暖化問題については多くの科学者が地球は温暖化していることを認めている。もちろん懐疑論は少なからずあるが、地球が温暖化していることそのものを否定する論はごく稀だ。
さて、そうした前提を踏まえて次のグラフを見てもらいたい。

このグラフを見ると地球は温暖化などしていないように見える。
事実、このグラフは、地球温暖化について見極めることなど不可能だという主張の根拠として使われたのだ。
このグラフは、スティーヴン・ヘイワードがパワーラインというブログのためにつくり、2015年後半にナショナル・レビューがTwitterに投稿して広くシェアされた地球の平均気温に関するグラフだ。
このグラフに使われる数字とデータ自体は何も間違ってはいない。
データインク比も正常であるし、ベースラインが0から始まっているためライファクター(lie factor)も1(正常)となる。ライファクター(lie factor)という指数でみれば完全に正確なグラフと判定されるものだ(参考:The Lie Factor and the Baseline Paradox | Nightingale)。
しかし、このグラフは明らかにスティーヴン・ヘイワードの主観的な意図を反映している。
実際に多くの科学者が認める通り地球は温暖化しており、このグラフのライファクター(lie factor)が1の正確なグラフと判定がされようが、明らかに受け手を誤解させ騙すものになっている。
同じデータを使ったとしても、恐らく次のような表現の方が地球の温度変化を示す上で適切だ。

このように、そもそもデータを示す際の適切で正しい表現とは何かということについて、最終的にそれを検討して判断するのは人間である。
最初に引用したMRJの例では、図の棒グラフの表現は「20%感」が全くない(むしろ誤解させる)表現とされていたが、燃費における「20%感」とはなんなのかを客観的に示すことはできない。むしろ、図の棒グラフの表現の方が「20%感」があると感じる人はいるかもしれない。
地球温暖化に関するグラフも、ライファクター(lie factor)が1なのだからスティーヴン・ヘイワードのグラフの方が正しいと主張する人もきっといるだろう。
あるいは、ライファクター(lie factor)とは別の指標を持ち出す人もいるだろうし、それに反対する人もいるだろう。数字さえ間違っていないのなら間違った表現方法など存在しないという主張もあるかもしれない。
データというものには、どのようにデザインしてそれを見せるかという表現形態の次元が付きまとっているのだ。
4.データはメディアであり表現である
統計やデータというものは、人の主観に依らない客観的事実を示していると言う人がいる。
しかし、何を以て統計は主観的ではないと言えるのだろうか?
統計もメディアと同じように、人間が情報収集の範囲を定め、なおかつその見せ方(デザイン)を選び編集したものである。
統計やデータは事実そのものではなく、仮説を立てた人間の現実理解の枠組みを数字で表現したものである。
言い換えれば、ある事実に対する一つの解釈を数値化して表現したものだ。
数値化されているから現実のありのままを示している、なんてことはない。
数字に変換している時点で現実の意味の一部は失われている。数字によって見えてくる現実とは、数字によって意味が単純化された現実であり、ある意味で歪められた現実である。
私たちはメディアに対する姿勢と同じ姿勢で統計に臨む必要がある。
メディアの情報は正しいかもしれないし、偏向しているかもしれない。それと同じように、統計も正しいかもしれないし、偏向しているかもしれない。
統計データを含め、私たちの周りに偏向していない情報などない。情報収集のリソースには限界があり、常に情報の取捨選択が起こっている。必要な情報ではないと判断された情報が真実かもしれないし、見落とされてしまっている真実もあるかもしれない。
私たちは統計は編集されたものであることを認識して、見せかけの事実である可能性を考慮してそれが事実かどうかを判断しなければならない。
議論で統計やデータを盲目に信じる人は、メディアの情報に踊らされる人間と大差ない。
それでも、統計やデータがないよりはマシだと言う人はいるだろう。
統計やデータを基に仮説を立てる場合、少なくともデータと全く矛盾するような自分勝手な妄想を述べることはできないし、データの見せ方を編集して変えたとしてもそれは検証可能なので、その作為を見破られるだろうという反論が想定される。
つまり、どのみち主観を完全に取り去ることは不可能だが、統計やデータに基づいた議論では一定の慎重さとコストが要求されるため、少なくとも互いに好き勝手な妄想を語ることはできないし互いの主張を検証可能だ、と彼らは言いたいわけだ。
しかしこの手主張は、そもそも社会についての議論をする場合に、統計やデータというものがどこまで信頼し頼ることのできるものなのだろうかという根本の視点が抜けてしまっているのだ。
第一に、社会問題の議論でデータを集計することそのものの難しさを理解していない。その他科学の領域と違い、社会的な事実を確認するためのデータ集めは一筋縄ではいかない。
第二に、人間がどのようにデータを理解し利用しているのかという手つきをまるで見ていない。データを出して議論をすれば、おそらく互いに好き勝手な妄想を語ることはできないだろうという安易で楽観的な予測は、人間社会に対する単純な誤解に満ちている。
そこで次回は、社会についての統計やデータを扱うことの難しさについて説明することにしたい。
【次回記事】
tatsumi-kyotaro.hatenablog.com
【今回の参考文献】
↓第9章の「科学のもろさ」では、懐疑的な態度を徹底しているはずの科学という領域でさえもデタラメが絶えないということを様々な事例とともに紹介している。
↓前回の『統計はこうしてウソをつく―だまされないための統計学入門』から、さらに踏み込んで、統計というもの自体が不可避的にウソの要素を含んでしまうということを示唆する内容となっている。
↓いわゆるデータリテラシー本。
